Availability is an important characteristic
— Mike Fisher, former CTO of Etsy
“I am getting knocked down, however I rise up once more…”
— Tubthumping, Chumbawumba
Each and every group will pay consideration to resilience. The massive query is
when.
Startups have a tendency to simply cope with resilience when their programs are already
down, steadily taking an overly reactive manner. For a scaleup, over the top machine
downtime represents a vital bottleneck to the group, each from
the hassle expended on restoring serve as and likewise from the affect of shopper
dissatisfaction.
To transport previous this, resilience must be constructed into the industry
goals, which can affect the structure, design, product
control, or even governance of industrial programs. On this article, we’ll
discover the Resilience and Observability Bottleneck: how you’ll be able to acknowledge
it coming, how chances are you’ll know it has already arrived, and what you’ll be able to do
to live to tell the tale the bottleneck.
How did you get into the bottleneck?
Some of the first targets of a startup is getting an preliminary product out
to marketplace. Getting it in entrance of as many customers as imaginable and receiving
comments from them is most often the easiest precedence. If consumers use
your product and notice the original price it delivers, your startup will carve
out marketplace proportion and feature a unswerving income move. On the other hand, getting
there steadily comes at a value to the resilience of your product.
A startup might make a decision to skip automating restoration processes, as a result of at
a small scale, the group believes it can give resilience via
the builders that know the machine nicely. Incidents are treated in a
reactive nature, and resolutions come through hand. Imaginable answers could be
spinning up any other example to take care of larger load, or restarting a
provider when it’s failing. Your first consumers may even take note of
your loss of true resilience as they revel in machine outages.
At one in all our scaleup engagements, to get the machine out to manufacturing
briefly, the buyer deprioritized well being test mechanisms within the
cluster. The builders controlled the startup procedure effectively for the
few occasions when it used to be important. For the most important demo, it used to be made up our minds to
spin up a brand new cluster in order that there could be no externalities impacting
the machine efficiency. Sadly, actively managing the standing of all
the products and services working within the cluster used to be overpassed. The demo began
earlier than the machine used to be absolutely operational and the most important element of the
machine failed in entrance of potential consumers.
Basically, your company has made an specific trade-off
prioritizing user-facing capability over automating resilience,
playing that the group can recuperate from downtime via guide
intervention. The trade-off is most likely appropriate as a startup whilst it’s
at a manageable scale. On the other hand, as you revel in prime progress charges and
turn into from a
startup to a scaleup, the loss of resilience proves to be a scaling
bottleneck, manifesting as an expanding prevalence of provider
interruptions translating into extra paintings at the Ops aspect of the DevOps
group’s obligations, decreasing the productiveness of groups. The affect
turns out to seem , since the impact has a tendency to be non-linear
relative to the expansion of the client base. What used to be just lately manageable
is extraordinarily impactful. In the end, the dimensions of the machine
creates guide paintings past the capability of your group, which bubbles as much as
impact the client stories. The mix of lowered productiveness
and buyer dissatisfaction results in a bottleneck this is laborious to
live to tell the tale.
The query then is, how do I do know if my product is set to hit a
scaling bottleneck? And extra, if I learn about the ones indicators, how can I
keep away from or stay tempo with my scale? That’s what we’ll glance to respond to as we
describe commonplace demanding situations we’ve skilled with our purchasers and the
answers we’ve got noticed to be most efficient.
Indicators you might be coming near a scaling bottleneck
It is all the time tough to function in an atmosphere by which the dimensions
of the industry is converting hastily. Making an investment in dealing with prime site visitors
volumes too early is a waste of assets. Making an investment too overdue manner your
consumers are already feeling the consequences of the scaling bottleneck.
To shift your running type from reactive to proactive, you need to
have the ability to expect long run conduct with a self belief degree enough to
beef up necessary industry selections. Making information pushed selections is
all the time the objective. The secret’s to search out the main signs which can
information you to organize for, and with a bit of luck keep away from the bottleneck, moderately than
react to a bottleneck that has already came about. In line with our revel in,
we’ve got discovered a collection of signs associated with the typical preconditions as
you manner this bottleneck.
Resilience isn’t a first-class attention
This can be the least evident signal, however is arguably an important.
Resilience is regarded as purely a technical issue and no longer a characteristic
of the product. It’s deprioritized for brand new options and improvements. In
some circumstances, it’s no longer even a priority to be prioritized.
Right here’s a handy guide a rough check. Eavesdrop on the other discussions that
happen inside your groups, and notice the context by which resilience is
mentioned. Chances are you’ll to find that it isn’t integrated as a part of a standup, however
it does make its approach right into a developer assembly. When the improvement group isn’t
chargeable for operations, resilience is successfully siloed away.
In the ones circumstances, pay shut consideration to how resilience is mentioned.
Proof of insufficient center of attention on resilience is steadily oblique. At one
shopper, we’ve noticed it come within the type of technical debt playing cards that no longer
best aren’t prioritized, however turn into a relentless rising record. At any other
shopper, the operations group had their backlog crammed purely with
buyer incidents, nearly all of which handled the machine both
no longer being up or being not able to procedure requests. When resilience issues
aren’t a part of a group’s backlog and roadmap, you’ll have proof that
it isn’t core to the product.
Fixing resilience through hand (reactive guide resilience)
How your company unravel provider outages generally is a key indicator
of whether or not your product can scaleup successfully or no longer. The traits
we describe listed below are basically led to through a
loss of automation, leading to over the top guide effort. Are provider
outages resolved by the use of restarts through builders? Below prime load, is there
coordination required to scale compute cases?
Typically, we discover
those approaches don’t apply sustainable operational practices and are
brittle answers for the following machine outage. They come with bandaid answers
which alleviate a symptom, however by no means in point of fact remedy it in some way that permits
for long run resilience.
Possession of programs aren’t nicely explained
When your company is transferring briefly, creating new products and services and
functions, slightly steadily key items of the provider ecosystem, and even
the infrastructure, can turn into “orphaned” – with out transparent duty
for operations. In consequence, manufacturing problems might stay overlooked till
consumers react. Once they do happen, it takes longer to troubleshoot which
reasons delays in resolving outages. Answer is not on time whilst ping ponging problems
between groups so to to find the accountable social gathering, losing
everybody’s time as the problem bounces from group to group.
This issue isn’t distinctive to microservice environments. At one
engagement, we witnessed identical eventualities with a monolith structure
missing transparent possession for portions of the machine. On this case, readability
of possession problems stemmed from a loss of transparent machine limitations in a
“ball of dust” monolith.
Ignoring the truth of disbursed programs
A part of creating efficient programs is with the ability to outline and use
abstractions that allow us to simplify a fancy machine to the purpose
that it in fact suits within the developer’s head. This permits builders to
make selections in regards to the long run adjustments important to ship new price
and capability to the industry. On the other hand, as in all issues, one can pass
too a long way, no longer figuring out that those simplifications are in fact
assumptions hiding crucial constraints which affect the machine.
Riffing off the fallacies of distributed computing:
- The community isn’t dependable.
- Your machine is suffering from the velocity of sunshine. Latency is rarely 0.
- Bandwidth is finite.
- The community isn’t inherently protected.
- Topology all the time adjustments, through design.
- The community and your programs are heterogeneous. Other programs behave
another way beneath load. - Your digital device will disappear whilst you least be expecting it, at precisely the
incorrect time. - As a result of folks have get admission to to a keyboard and mouse, errors will
occur. - Your consumers can (and can) take their subsequent motion in <
500ms.
Very steadily, trying out environments supply absolute best global
prerequisites, which avoids violating those assumptions. Programs which
don’t account for (and check for) those real-world homes are
designed for an international by which not anything dangerous ever occurs. In consequence,
your machine will show off unanticipated and reputedly non-deterministic
conduct because the machine begins to violate the hidden assumptions. This
interprets into deficient efficiency for purchasers, and extremely tough
troubleshooting processes.
No longer making plans for doable site visitors
Estimating long run site visitors quantity is hard, and we discover that we
are incorrect extra steadily than we’re proper. Over-estimating site visitors manner
the group is losing effort designing for a fact that doesn’t
exist. Below-estimating site visitors may well be much more catastrophic. Sudden
prime site visitors rather a lot may just occur for a number of causes, and a social media advertising and marketing
marketing campaign which abruptly is going viral is a great instance. All at once your
machine can’t set up the incoming site visitors, parts begin to fall over,
and the whole lot grinds to a halt.
As a startup, you’re all the time taking a look to draw new consumers and achieve
further marketplace proportion. How and when that manifests can also be extremely
tough to expect. On the scale of the web, anything else may just occur,
and also you must suppose that it’ll.
Alerted by the use of buyer notifications
When consumers are invested on your product and imagine the problem is
resolvable, they may attempt to touch your beef up personnel for
assist. That can be via electronic mail, calling in, or opening a beef up
price tag. Provider screw ups purpose spikes in name quantity or electronic mail site visitors.
Your gross sales folks can even be relaying those messages as a result of
(doable) consumers are telling them as nicely. And if provider outages
impact strategic consumers, your CEO may let you know without delay (this can be
ok early on, but it surely’s not at all a state you wish to have to be in long run).
Buyer communications won’t all the time be transparent and simple, however
moderately shall be in keeping with a buyer’s distinctive revel in. If buyer good fortune personnel
don’t notice that those are indications of resilience issues,
they are going to continue with industry as standard and your engineering personnel will
no longer obtain the comments. Once they aren’t known and controlled
appropriately, notifications might then flip non-verbal. As an example, you might
to find the velocity at which consumers are canceling subscriptions
will increase.
When operating with a small buyer base, understanding about an issue
via your consumers is “most commonly” manageable, as they’re quite
forgiving (they’re in this adventure with you in spite of everything). On the other hand, as
your buyer base grows, notifications will start to pile up in opposition to
an unmanageable state.
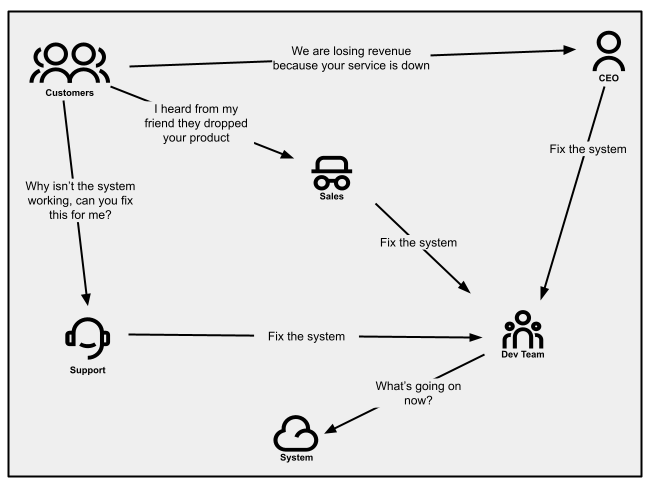
Determine 1:
Conversation patterns as noticed in a corporation the place buyer notifications
aren’t controlled nicely.
How do you get out of the bottleneck?
Upon getting an outage, you wish to have to recuperate as briefly as imaginable and
perceive intimately why it took place, so you’ll be able to give a boost to your machine and
make sure it by no means occurs once more.
Tackling the resilience of your services and products whilst within the bottleneck
can also be tough. Tactical answers steadily imply you find yourself caught in hearth after hearth.
On the other hand if it’s controlled strategically, even whilst within the bottleneck, no longer
best are you able to relieve the power in your groups, however you’ll be able to be told from previous restoration
efforts to assist set up during the hypergrowth degree and past.
The next 5 sections are successfully methods your company can enforce.
We imagine they drift so as and must be taken as an entire. On the other hand, relying
in your group’s adulthood, you might make a decision to leverage a subset of
methods. Inside of every, we lay out a number of answers that paintings in opposition to it is
respective technique.
Be sure to have carried out elementary resilience tactics
There are some elementary tactics, starting from structure to
group, that may give a boost to your resiliency. They preserve your product
in the proper position, enabling your company to scale successfully.
Use more than one zones inside a area
For extremely crucial products and services (and their information), configure and allow
them to run throughout more than one zones. This must give a bump on your
machine availability, and building up your resiliency relating to
disruption (inside a zone).
Specify suitable computing example sorts and specs
Industry crucial products and services must have computing capability
correctly assigned to them. If products and services are required to run 24/7,
your infrastructure must mirror the ones necessities.
Fit funding to crucial provider tiers
Many organizations set up funding through figuring out crucial
provider tiers, with the figuring out that no longer all industry programs
proportion the similar significance relating to turning in buyer revel in
and supporting income. Figuring out provider tiers and related
resilience results knowledgeable through provider degree agreements (SLAs), paired with structure and
design patterns that beef up the results, supplies useful guardrails
and governance in your product construction groups.
Obviously outline homeowners throughout your whole machine
Each and every provider that exists inside your machine must have
well-defined homeowners. This data can be utilized to assist direct problems
to the proper position, and to those who can successfully unravel them.
Imposing a developer portal which supplies a device products and services
catalog with obviously explained group possession is helping with inside
communique patterns.
Automate guide resilience processes (inside a timebox)
Sure resilience issues which were solved through hand can also be
automatic: movements like restarting a provider, including new cases or
restoring database backups. Many movements are simply automatic or just
require a configuration trade inside your cloud provider supplier.
Whilst within the bottleneck, enforcing those functions can provide the
group the relaxation it wishes, offering a lot wanted respiring room and
time to resolve the basis purpose(s).
You’ll want to stay those implementations at their most simple and
timeboxed (couple of days at max). Take into accout those began out as
bandaids, and automating them is simply any other (albeit higher) form of
bandaid. Combine those into your tracking resolution, permitting you
to stay conscious about how ceaselessly your machine is mechanically convalescing and the way lengthy it
takes. On the identical time, those metrics let you prioritize
transferring clear of reliance on those bandaid answers and make your
entire machine extra powerful.
Fortify imply time to revive with observability and tracking
To paintings your approach out of a bottleneck, you wish to have to grasp your
present state so you’ll be able to make efficient selections about the place to speculate.
If you wish to be 5 nines, however haven’t any sense of what number of nines are
in fact recently supplied, then it’s laborious to even know what trail you
must be taking.
To grasp the place you might be, you wish to have to spend money on observability.
Observability means that you can be extra proactive in timing funding in
resilience earlier than it turns into unmanageable.
Centralize your logs to be viewable via a unmarried interface
Combination logs from core products and services and programs to be to be had
via a central interface. This may increasingly stay them out there to
more than one eyes simply and cut back troubleshooting efforts (probably
making improvements to imply time to restoration).
Outline a transparent structured layout for log messages
Somebody who’s needed to parse via aggregated log messages can inform
you that once more than one products and services apply differing log buildings it’s
an out of this world mess to search out anything else. Each and every provider simply finally ends up
talking its personal language, and best the unique authors perceive
the logs. Preferably, as soon as the ones logs are aggregated, someone from
builders to beef up groups must have the ability to perceive the logs, no
subject their starting place.
Construction the log messages the usage of an organization-wide standardized
layout. Maximum logging gear beef up a JSON layout as a regular, which
allows the log message construction to comprise metadata like timestamp,
severity, provider and/or correlation-id. And with log control
products and services (via an observability platform), one can filter out and seek throughout those
homes to assist debug bottleneck problems. To assist in making seek extra
environment friendly, choose fewer log messages with extra fields containing
pertinent knowledge over many messages with a small choice of
fields. The real messages themselves might nonetheless be distinctive to a
explicit provider, however the attributes related to the log message
are useful to everybody.
Deal with your log messages as a key piece of data this is
visual to extra than simply the builders that wrote them. Your beef up group can
turn into simpler when debugging preliminary buyer queries, as a result of
they are able to perceive the construction they’re viewing. If each and every provider
can discuss the similar language, the barrier to offer beef up and
debugging help is got rid of.
Upload observability that’s with regards to your buyer revel in
What will get measured will get controlled.
— Peter Drucker
Although infrastructure metrics and repair message logs are
helpful, they’re quite low degree and don’t supply any context of
the real buyer revel in. Alternatively, buyer
notifications are an immediate indication of a subject matter, however they’re
most often anecdotal and don’t supply a lot relating to development (until
you place within the paintings to search out one).
Tracking core industry metrics allows groups to look at a
buyer’s revel in. Usually explained during the product’s
necessities and lines, they supply prime degree context round
many buyer stories. Those are metrics like finished
transactions, get started and forestall price of a video, API utilization or reaction
time metrics. Implicit metrics also are helpful in measuring a
buyer’s stories, like frontend load time or seek reaction
time. It is an important to compare what’s being noticed without delay
to how a buyer is experiencing your product. Additionally
necessary to notice, metrics aligned to the client revel in turn into
much more necessary in a B2B atmosphere, the place chances are you’ll no longer have
the quantity of knowledge issues important to pay attention to buyer problems
when best measuring person parts of a machine.
At one shopper, products and services began to submit area occasions that
have been associated with the product revel in: occasions like added to cart,
failed so as to add to cart, transaction finished, fee authorized, and so on.
Those occasions may just then be picked up through an observability platform (like
Splunk, ELK or Datadog) and displayed on a dashboard, labeled and
analyzed even additional. Mistakes may well be captured and labeled, permitting
higher issue fixing on mistakes associated with sudden buyer
revel in.
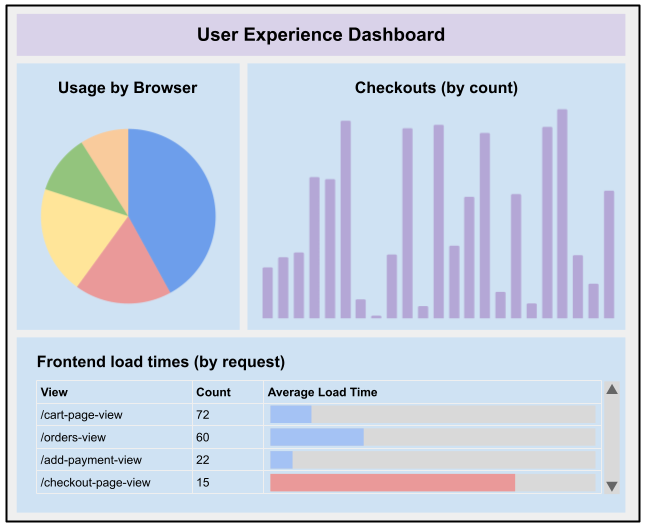
Determine 2:
Instance of what a dashboard that specialize in the consumer revel in may just seem like
Knowledge accumulated via core industry metrics permit you to perceive
no longer best what could be failing, however the place your machine thresholds are and
the way it manages when it’s out of doors of that. This offers additional perception into
how chances are you’ll get during the bottleneck.
Supply product standing perception to consumers the usage of standing signs
It may be tough to control incoming buyer inquiries of
other problems they’re going through, with beef up products and services briefly discovering
they’re combating hearth after hearth. Managing factor quantity can also be an important
to a startup’s good fortune, however throughout the bottleneck, you wish to have to search for
systemic tactics of decreasing that site visitors. The power to divert name
site visitors clear of beef up will give some respiring room and a greater likelihood to
remedy the proper issue.
Provider standing signs can give consumers the ideas they’re
searching for with no need to succeed in out to beef up. This is able to are available in
the type of public dashboards, electronic mail messages, and even tweets. Those can
leverage backend provider well being and readiness tests, or a mixture
of metrics to decide provider availability, degradation, and outages.
All over occasions of incidents, standing signs can give some way of updating
many purchasers immediately about your product’s standing.
Construction accept as true with together with your consumers is simply as necessary as making a
dependable and resilient provider. Offering strategies for purchasers to grasp
the products and services’ standing and anticipated answer time frame is helping construct
self belief via transparency, whilst additionally giving the beef up personnel
the distance to problem-solve.
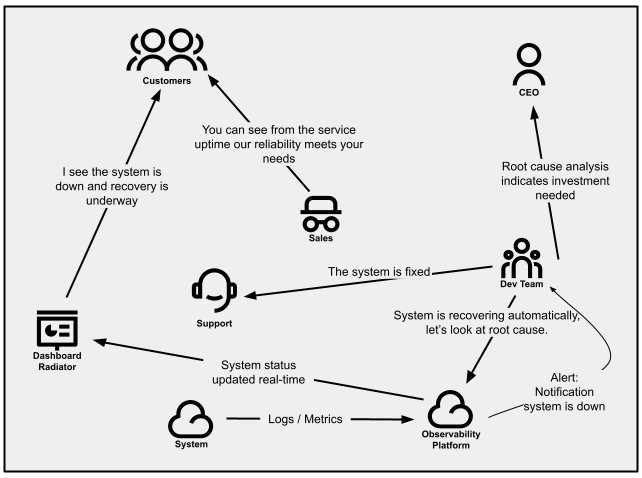
Determine 3:
Conversation patterns inside a corporation that proactively manages how consumers are notified.
Shift to specific resilience industry necessities
As a startup, new options are steadily thought to be extra treasured
than technical debt, together with any paintings associated with resilience. And as mentioned
earlier than, this without a doubt made sense to start with. New options and
improvements assist stay consumers and usher in new ones. The paintings to
supply new functions must, in concept, result in an building up in
income.
This doesn’t essentially grasp true as your company
grows and discovers new demanding situations to expanding income. Screw ups of
resilience are one supply of such demanding situations. To transport past this, there
must be a shift in the way you price the resilience of your product.
Perceive the prices of provider failure
For a startup, the effects of no longer hitting a income goal
this ‘quarter’ could be other than for a scaleup or a mature
product. However as steadily occurs, the preliminary “new options are extra
treasured than technical debt” resolution turns into an enduring fixture within the
organizational tradition – whether or not the real income affect is provable
or no longer; and even calculated. A facet of the adulthood wanted when
transferring from startup to scaleup is within the data-driven component of
decision-making. Is the group monitoring the worth of each and every new
characteristic shipped? And is the group inspecting the operational
investments as contributing to new income moderately than only a
cost-center? And are the prices of an outage or routine outages recognized
each relating to wasted inside exertions hours in addition to misplaced income?
As a startup, in these kind of regards, you have got not anything to lose.
However this isn’t true as you develop.
Subsequently, it’s necessary to start out inspecting the prices of provider
screw ups as a part of your general product control and income
reputation price move. Figuring out your income “speed” will
supply a very easy solution to quantify the direct cost-per-minute of
downtime. Monitoring the prices to the group for everybody enthusiastic about an
outage incident, from buyer beef up calls to builders to control
to public family members/advertising and marketing or even to gross sales, can also be an eye-opening revel in.
Upload at the alternative prices of coping with an outage moderately than
increasing buyer outreach or turning in new options and the actual
scope and affect of screw ups in resilience turn into obvious.
Set up resilience as a characteristic
Get started treating resilience as greater than only a technical
expectation. It’s a core characteristic that consumers will come to be expecting.
And since they be expecting it, it must turn into a first-class
attention amongst different options. A part of this evolution is set transferring the place the
duty lies. As an alternative of it being purely a duty for
tech, it’s one for product and the industry. More than one layers inside
the group will want to believe resilience a concern. This
demonstrates that resilience will get an identical quantity of consideration that
another characteristic would get.
Close collaboration between
the product and technology is important to you’ll want to’re in a position to
set the right kind expectancies throughout tale definition, implementation
and communique to different portions of the group. Resilience,
even though a core characteristic, continues to be invisible to the client (not like new
options like additions to a UI or API). Those two teams want to
collaborate to verify resilience is prioritized correctly and
carried out successfully.
The target this is transferring resilience from being a reactionary
fear to a proactive one. And in case your groups are in a position to be
proactive, you’ll be able to additionally react extra correctly when one thing
vital is going on to your corporation.
Necessities must mirror real looking expectancies
Figuring out real looking expectancies for resilience relative to
necessities and buyer expectancies is vital to retaining your
engineering efforts charge efficient. Other ranges of resilience, as
measured through uptime and availability, have hugely other prices. The
charge distinction between “3 nines” and “4 nines” of availability
(99.9% vs 99.99%) could also be an element of 10x.
It’s necessary to grasp your buyer necessities for every
industry capacity. Do you and your consumers be expecting a 24x7x365
revel in? The place are your consumers
based totally? Are they native to a particular area or are they world?
Are they essentially eating your provider by the use of cellular units, or are
your consumers built-in by the use of your public API? As an example, it’s an
useless use of capital to offer 99.999% uptime on a provider delivered by the use of
cellular units which best revel in 99.9% uptime because of mobile phone
reliability limits.
Those are necessary questions to invite
when serious about resilience, since you don’t need to pay for the
implementation of a degree of resiliency that has no perceived buyer
price. Additionally they assist to set and set up
expectancies for the product being constructed, the group construction and
keeping up it, the parents on your group promoting it and the
consumers the usage of it.
Really feel out your issues first and keep away from overengineering
If you happen to’re fixing resiliency issues through hand, your first intuition
could be to simply automate it. Why no longer, proper? Although it may well assist, it is maximum
efficient when the implementation is time-boxed to an overly quick length
(a few days at max). Spending extra time will most likely result in
overengineering in a space that used to be in fact only a symptom.
A considerable amount of time, power and cash shall be invested into one thing this is
simply any other bandaid and in all probability isn’t sustainable, and even worse,
reasons its personal set of second-order demanding situations.
As an alternative of going immediately to a tactical resolution, that is an
alternative to truly really feel out your issue: The place do the fault strains
exist, what’s your observability looking to let you know, and what design
possible choices correlate to those screw ups. You might be able to uncover the ones
fault strains via tension, chaos or exploratory trying out. Use this
alternative on your benefit to find different machine tension issues
and decide the place you’ll be able to get the biggest price in your funding.
As your corporation grows and scales, it’s crucial to re-examine
previous selections. What made sense throughout the startup segment won’t get
you during the hypergrowth phases.
Leverage more than one tactics when accumulating necessities
Accumulating necessities for technically orientated options
can also be tough. Product managers or industry analysts who aren’t
versed within the nomenclature of resilience can to find it laborious to
perceive. This steadily interprets into imprecise necessities like “Make x provider
extra resilient” or “100% uptime is our objective”. The necessities you outline are as
necessary because the ensuing implementations. There are lots of tactics
that may assist us collect the ones necessities.
Take a look at working a pre-mortem earlier than writing necessities. On this
light-weight job, people in several roles give their
views about what they suspect may just fail, or what’s failing. A
pre-mortem supplies treasured insights into how people understand
doable reasons of failure, and the comparable prices. The following
dialogue is helping prioritize issues that want to be made resilient,
earlier than any failure happens. At a minimal, you’ll be able to create new check
eventualities to additional validate machine resilience.
An alternative choice is to write down necessities along tech leads and
structure SMEs. The duty to create an efficient resilient machine
is now shared among leaders at the group, and every can discuss to
other sides of the design.
Those two tactics display that necessities accumulating for
resilience options isn’t a unmarried duty. It must be shared
throughout other roles inside a group. Right through each and every methodology you
check out, be mindful who must be concerned and the views they create.
Evolve your structure and infrastructure to satisfy resiliency wishes
For a startup, the design of the structure is dictated through the
velocity at which you’ll be able to get to marketplace. That steadily manner the design that
labored to start with can turn into a bottleneck on your transition to scaleup.
Your product’s resilience will in the end come right down to the generation
possible choices you are making. It will imply inspecting your general design and
structure of the machine and evolving it to satisfy the product
resilience wishes. A lot of what we spoke to previous can assist provide you with
information issues and slack throughout the bottleneck. Inside of that house, you’ll be able to
evolve the structure and incorporate patterns that allow a in point of fact
resilient product.
Widely take a look at your structure and decide suitable trade-offs
Both implicitly or explicitly, when the preliminary structure used to be
created, trade-offs have been made. All over the experimentation and gaining
traction levels of a startup, there’s a prime stage of center of attention on
getting one thing to marketplace briefly, retaining construction prices low,
and with the ability to simply adjust or pivot product course. The
trade-off is sacrificing the advantages of resilience
that may come out of your superb structure.
Take an API sponsored through Purposes as a Provider (FaaS). This manner is a good way to
create one thing with little to no control of the infrastructure it
runs on, probably ticking all 3 containers of our center of attention house. At the
different hand, it is restricted in keeping with the infrastructure it’s allowed to
run on, timing constraints of the provider and the prospective
communique complexity between many alternative purposes. Although no longer
unachievable, the restrictions of the structure might make it
tough or advanced to succeed in the resilience your product wishes.
Because the product and group grows and matures, its constraints
additionally evolve. It’s necessary to recognize that early design selections
might now not be suitable to the present running atmosphere, and
as a result new architectures and applied sciences want to be offered.
If no longer addressed, the trade-offs made early on will best magnify the
bottleneck throughout the hypergrowth segment.
Give a boost to resilience with efficient error restoration methods
Knowledge accumulated from displays can display the place prime failure
charges are coming from, be it third-party integrations, backed-up queues,
backoffs or others. This knowledge can pressure selections on what are
suitable restoration methods to enforce.
Use caching the place suitable
When retrieving knowledge, caching methods can assist in two
tactics. Basically, they are able to be used to scale back the burden at the provider through
offering cached effects for a similar queries. Caching will also be
used because the fallback reaction when a backend provider fails to go back
effectively.
The trade-off is probably serving stale information to consumers, so
be sure that your use case isn’t delicate to stale information. As an example,
you wouldn’t need to use cached effects for real-time inventory value
queries.
Use default responses the place suitable
As an alternative choice to caching, which supplies the ultimate recognized
reaction for a question, it’s imaginable to offer a static default price
when the backend provider fails to go back effectively. As an example,
offering retail pricing because the fallback reaction for a pricing
bargain provider will do no hurt whether it is higher to possibility dropping a sale
moderately than possibility dropping cash on a transaction.
Use retry methods for mutation requests
The place a consumer is looking a provider to impact a metamorphosis within the information,
the use case might require a a success request earlier than continuing. In
this example, retrying the decision could also be suitable with the intention to decrease
how steadily error control processes want to be hired.
There are some necessary trade-offs to believe. Retries with out
delays possibility inflicting a hurricane of requests which carry the entire machine
down beneath the burden. The usage of an exponential backoff prolong mitigates the
possibility of site visitors load, however as an alternative ties up connection sockets ready
for a long-running request, which reasons a special set of
screw ups.
Use idempotency to simplify error restoration
Shoppers enforcing any form of retry technique will probably
generate more than one an identical requests. Ensure that the provider can take care of
more than one an identical mutation requests, and too can take care of resuming a
multi-step workflow from the purpose of failure.
Design industry suitable failure modes
In a machine, failure is a given and your objective is to offer protection to the top
consumer revel in up to imaginable. Particularly in circumstances which might be
supported through downstream products and services, you might be able to watch for
screw ups (via observability) and supply an alternate drift. Your
underlying products and services that leverage those integrations can also be designed
with industry suitable failure modes.
Believe an ecommerce machine supported through a microservice
structure. Must downstream products and services supporting the ordering
serve as turn into beaten, it could be extra suitable to
quickly disable the order button and provide a restricted error
message to a buyer. Whilst this offers transparent comments to the consumer,
Product Managers interested by gross sales conversions may as an alternative permit
for orders to be captured and alert the client to a prolong so as
affirmation.
Failure modes must be embedded into upstream programs, with the intention to make sure
industry continuity and buyer pleasure. Relying in your
structure, this may contain your CDN or API gateway returning
cached responses if requests are overloading your subsystems. Or as
described above, your machine may supply for an alternate trail to
eventual consistency for explicit failure modes. It is a way more
efficient and buyer centered manner than the presentation of a
generic error web page that conveys ‘one thing has long past incorrect’.
Unravel unmarried issues of failure
A unmarried provider can simply pass from managing a unmarried
duty of the product to more than one. For a startup, appending to
an present provider is steadily the most simple manner, because the
infrastructure and deployment trail is already solved. On the other hand,
products and services can simply bloat and turn into a monolith, developing some degree of
failure that may carry down many or all portions of the product. In circumstances
like this, you’ll be able to want to perceive tactics to separate up the structure,
whilst additionally retaining the product as an entire useful.
At a fintech shopper, throughout a hyper-growth length, load
on their monolithic machine would spike wildly. Because of the monolithic
nature, all the purposes have been introduced down concurrently,
leading to misplaced income and unsatisfied consumers. The long-term
resolution used to be to start out splitting the monolith into a number of separate
products and services which may be scaled horizontally. As well as, they
offered match queues, so transactions have been by no means misplaced.
Imposing a microservice manner isn’t a easy and simple
activity, and does take effort and time. Get started through defining a site that
calls for a resiliency spice up, and extract it is functions piece through piece.
Roll out the brand new provider, modify infrastructure configuration as wanted (building up
provisioned capability, enforce auto scaling, and so on) and track it.
Make sure that the consumer adventure hasn’t been affected, and resilience as
an entire has advanced. As soon as balance is completed, proceed to iterate over
every capacity within the area. As famous within the shopper instance, that is
additionally a chance to introduce architectural parts that assist building up
the overall resilience of your machine. Tournament queues, circuit breakers, bulkheads and
anti-corruption layers are all helpful architectural parts that
building up the full reliability of the machine.
Frequently optimize your resilience
It is something to get during the bottleneck, it is any other to stick
out of it. As you develop, your machine resiliency shall be regularly
examined. New options lead to new pathways for larger machine load.
Architectural adjustments introduces unknown machine balance. Your
group will want to keep forward of what is going to in the end come. Because it
matures and grows, so must your funding into resilience.
Ceaselessly chaos check to validate machine resilience
Chaos engineering is the bedrock of in point of fact resilient merchandise. The
core price is the power to generate failure in ways in which chances are you’ll
by no means recall to mind. And whilst that chaos is developing screw ups, working
via consumer eventualities on the identical time is helping to grasp the consumer
revel in. This can give self belief that your machine can face up to
sudden chaos. On the identical time, it identifies which consumer
stories are impacted through machine screw ups, giving context on what to
give a boost to subsequent.
Although you might really feel extra comfy trying out towards a dev or QA
atmosphere, the worth of chaos trying out comes from manufacturing or
production-like environments. The objective is to know how resilient
the machine is within the face of chaos. Early environments are (most often)
no longer provisioned with the similar configurations present in manufacturing, thus
won’t give you the self belief wanted. Operating a check like
this in manufacturing can also be daunting, so you’ll want to trust in
your talent to revive provider. This implies all of the machine can also be
spun again up and knowledge can also be restored if wanted, during automation.
Get started with small comprehensible eventualities that can provide helpful information.
As you achieve revel in and self belief, believe the usage of your load/efficiency
exams to simulate customers when you execute your chaos trying out. Ensure that groups and
stakeholders are conscious that an experiment is set to be run, in order that they
are ready to watch (in case issues pass incorrect). Frameworks like
Litmus or Gremlin can give construction to chaos engineering. As
self belief and adulthood on your resilience grows, you’ll be able to begin to run
experiments the place groups aren’t alerted previously.
Recruit consultants with wisdom of resilience at scale
Hiring generalists when construction and turning in an preliminary product
is smart. Money and time are extremely treasured, so having
generalists supplies the versatility to verify you’ll be able to get out to
marketplace briefly and no longer devour away on the preliminary funding. On the other hand,
the groups have taken on greater than they are able to take care of and as your product
scales, what used to be as soon as just right sufficient is now not the case. A fairly
risky machine that made it to marketplace will proceed to get extra
risky as you scale, since the talents required to control it have
overtaken the talents of the present group. In the similar vein as
technical
debt,
this is a slippery slope and if no longer addressed, the issue will
proceed to compound.
To maintain the resilience of your product, you’ll want to recruit
for that experience to concentrate on that capacity. Mavens usher in a
contemporary view at the machine in position, together with their talent to
determine gaps and spaces for growth. Their previous stories can
have a two-fold impact at the group, offering a lot wanted steerage in
spaces that sorely want it, and an extra funding within the progress of
your workers.
All the time care for or give a boost to your reliability
In 2021, the State of Devops record expanded the fifth key metric from availability to reliability.
Below operational efficiency, it asserts a product’s talent to
retain its guarantees. Resilience ties without delay into this, because it’s a
key industry capacity that may make sure your reliability.
With many organizations pushing extra ceaselessly to manufacturing,
there must be assurances that reliability stays the similar or will get higher.
Along with your observability and tracking in position, make sure what it
tells you suits what your provider degree goals (SLOs) state. With each and every deployment to
manufacturing, the displays must no longer deviate from what your SLAs
ensure. Sure deployment buildings, like blue/inexperienced or canary
(to some degree), can assist to validate the adjustments earlier than being
launched to a large target audience. Operating exams successfully in manufacturing
can building up self belief that your agreements haven’t swayed and
resilience has remained the similar or higher.
Resilience and observability as your company grows
Section 1
Experimenting
Prototype answers, with hyper center of attention on getting a product to marketplace briefly
Section 2
Getting Traction
Resilience and observability are manually carried out by the use of developer intervention
Prioritization for fixing resilience principally comes from technical debt
Dashboards mirror low degree products and services statistics like CPU and RAM
Majority of beef up problems are available in by the use of calls or textual content messages from consumers
Section 3
(Hyper) Expansion
Resilience is a core characteristic brought to consumers, prioritized in the similar vein as options
Observability is in a position to mirror the full buyer revel in, mirrored via dashboards and tracking
Re-architect or recreate problematic products and services, making improvements to the resilience within the procedure
Section 4
Optimizing
Platforms evolve from inside going through products and services, productizing observability and compute environments
Run periodic chaos engineering workout routines, with little to no understand
Increase groups with engineers which might be versed in resilience at scale
Abstract
As a scaleup, what determines your talent to successfully navigate the
hyper(progress) segment is partly tied to the resilience of your
product. The prime progress price begins to position power on a machine that used to be
evolved throughout the startup segment, and failure to handle the resilience of
that machine steadily ends up in a bottleneck.
To reduce possibility, resilience must be handled as a first class citizen.
The main points might range in line with your context, however at a prime degree the
following concerns can also be efficient:
- Resilience is a key characteristic of your product. It’s now not only a
technical element, however a key element that your consumers will come to be expecting,
transferring the corporate in opposition to a proactive manner. - Construct buyer standing signs to assist divert some beef up requests,
permitting respiring room in your group to resolve the necessary issues. - The client revel in must be mirrored inside your observability stack.
Track core industry metrics that mirror stories your consumers have. - Perceive what your dashboards and displays are telling you, to get a way
of what are probably the most crucial spaces to resolve. - Evolve your structure to satisfy your resiliency targets as you determine
explicit demanding situations. Preliminary designs might paintings at small scale however turn into
increasingly more restricting as you transition to a scaleup. - When architecting failure modes, to find tactics to fail which might be pleasant to the
client, serving to to verify continuity and buyer pleasure. - Outline real looking resilience expectancies in your product, and perceive the
barriers with which it’s being served. Use this information to offer your
consumers with efficient SLAs and cheap SLOs. - Optimize your resilience whilst you’re during the bottleneck. Make chaos
engineering a part of an ordinary apply or recruiting consultants.
Effectively incorporating those practices ends up in a long run group
the place resilience is constructed into industry goals, throughout all dimensions of
folks, procedure, and generation.